En el anterior artículo hablábamos de una aplicación para GNU/Linux que realiza OCR sobre imágenes.
Existen muchas webs que realizan este tipo de procesado (tenemos que subir la imagen y nos devuelven un archivo de texto). Normalmente tienen limitaciones de texto, de peso de imagen, de número de páginas, de formatos de salida aceptados, de tiempo…
Otra opción -que es la que os quería comentar en este pequeño post-, es usar Google Drive.
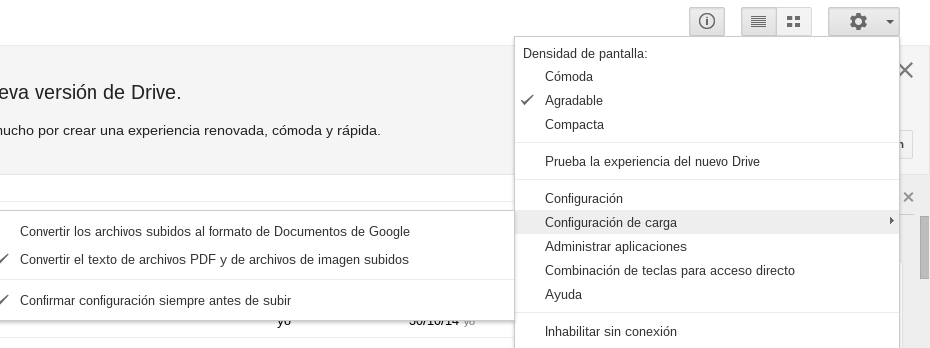
Para esto último tenemos que activar, dentro de Google Drive, las dos opciones que véis en la siguiente imagen (*):
Una vez hecho esto, cada vez que subamos un archivo de imagen o pdf nos preguntará si queremos convertirlo a texto.
Una vez hecho, cuando abramos el archivo aparecerá la imagen y a continuación todo el texto.
Hay una limitación de 10 hojas si se trata de un pdf. Para mejores resultados, y al igual que dijimos en el anterior artículo, tened en cuenta:
- Mejor cuando mayor contraste (blanco y negro mejor que escala de grises)
- Mejor cuanta más calidad tenga la imagen (sin pasarnos de peso en la imaegn, eso sí, que creo que es de 2 MB)
- Mejor si el formato es sencillo (negrita, cursiva, tamaño de letra). Si incluye tablas, múltiples columnas, etc., el resultado no será muy fiable.
(*) Si le habéis dado a «probar la nueva versión de Google Drive» esta opción no aparece y tendréis que volver a esta versión para poder usarla (es posible que esté ya en la nueva versión pero yo no la ví en su momento).