Introducción
La vida útil de los discos duros es limitada, y más con el uso que les damos actualmente; ¿quién no se ha comprado un disco de 1 TB y al poco tiempo lo tenía completamente lleno?
Por eso, es bueno hacer copias de seguridad con cierta periodicidad, dependiendo ésta de la criticidad de los datos (del valor que tengan para nosotros) y de la frecuencia de modificación de los mismos.
Si no tenemos la precaución de hacer estas copias de seguridad y ocurre un fallo en el disco duro es probable que perdamos todo, y la recuperación de nuestros archivos, si aún es posible, puede tener un coste que se puede escapar de un bolsillo normal y corriente (como el mío por ejemplo). Vamos, que en estos casos casi merece más la pena hacer de nuevo el viaje al Caribe que enviar el disco a reparar para recuperar las fotos del que hicimos el año pasado.
En ocasiones no se estropea completamente el disco, sino que da fallo en algún sector (sector es la unidad lógica mínima de un disco duro, para entendernos). Esto lo notamos cuando vamos a copiar un archivo a o desde un disco duro y se queda un rato «pensando», dando error de copia al final (normalmente de «redundancia cíclica»).
El que en un disco duro comiencen a fallar los sectores es señal de que es el principio del fin del mismo. Esto no tiene por qué suponer que haya que tirarlo, ni mucho menos, pero yo no dejaría en dicho disco mis fotos más preciadas (al menos, no sin tener un par de copias más en otros lugares).
A pesar de estos pequeños fallos podemos seguir utilizándolo con la particularidad de que cuando vaya a usar ese sector o sectores defectuosos probablemente volverá a dar fallo. ¿Cómo aislamos estos sectores de forma que el sistema operativo no los use más y así no provoque estos fallos? Esto es lo que vamos a tratar de contestar en lo que resta de post, porque vamos a ver cómo hacer esto (en GNU/linux, por supuesto) con distintas herramientas, como badblocks o fsck -entre otras-.
Badblocks
Cito de la Wikipedia (lo explican genial, como siempre): «badblocks es una utilidad disponible para Linux que permite localizar y aislar los sectores defectuosos de una unidad de disco».
Por tanto, ejecutando dicha utilidad (aunque se puede usar también como parte de la utilidad e2fsck) podemos recopilar una lista de sectores defectuosos encontrados. Esta lista la podemos guardar en un fichero de texto plano que luego podemos pasarle como argumento al comando que realiza el formateo para que tenga en cuenta dichos sectores defectuosos y no los use.
Por tanto, primero ejecutaríamos la utilidad badblocks sobre nuestro disco (pongamos que es, por ejemplo /dev/sdb, aunque podemos especificar también una partición, como «/dev/sdb5»):
# badblocks -svn /dev/sdb -o sectores_defectuosos.txt
donde:
-s –> muestra una barra de proceso
-v –> modo verbose (muestra los errores encontrados)
-n –> usa el modo no destructivo
-o –> especifica el fichero donde se guarda la salida
Al ejecutar dicho comando aparecerá algo como:
Revisando los bloques dañados en modo lectura-escritura no destructiva
Esto quiere decir que no se van a borrar los datos que tenemos en el disco. Aparecerá un porcentaje que va subiendo muy lentamente, así que armaros de paciencia porque es un proceso lento (pensad que va sector a sector y en un disco de 500 GB, por ejemplo, tiene más de 1000 millones de sectores (de 512 bytes cada uno).
Ahora formatearíamos el disco duro (o partición). Si lo queremos en fat32, lo haríamos así:
mkdosfs -F32 -v -l sectores_defectuosos.txt -n LABEL /dev/sdb
Si lo queremos en ext4 haríamos esto:
mkfs.ext4 -v -l sectores_defecuosos.txt -L LABEL /dev/sdb
donde:
-v –> modo verbose (muestra toda la salida de mensajes)
-l –> Le indicamos el fichero que contiene la lista de sectores defectuosos
-n/-L –> Especifica la etiqutea (LABEL o nombre de Volumen) del disco o partición (en mkdosfs esta opción es con «-n» y en mkfs.ext4 -en mke2fs en general- se usa la opción «-L»)
Otras posibilidades
Con mkfs.ext4
También se podría hacer ambas cosas al mismo tiempo de esta forma:
mkfs.ext4 -c /dev/sdb
donde:
-c Es para marcar los bloques defectuosos. Si pusiéramos -cc hace una búsqueda pero no destructiva
Con fsck.ext4
También se puede pasar un chequeo (con fsck) y pedirle que repare todos los fallos que encuentre:
fsck.ext4 -c -p /dev/sdb
donde:
-c (ídem del anterior)
-p Busca y repara los errores
Utilidades de los fabricantes de discos duros
Cada marca tiene su propia utilidad (la cuál, en principio, sólo vale para los discos de esa marca). Suelen funcionar bastante bien. En particular, yo he probado la de Seagate en alguna ocasión con buen resultado. En este caso, la utilidad se llama Seatools y tenéis la posibilidad de descargaros una iso con la que podéis arrancar (previo a quemar un CD con ella, obviamente) vuestro equipo y lanzarla directamente para revisar vuestro(s) disco(s) duro(s).
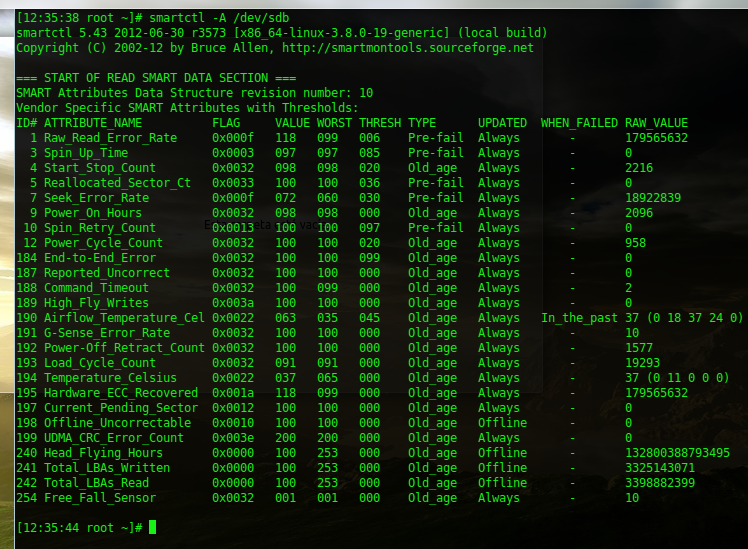
S.M.A.R.T
Por último, comentaros que existe una tecnología llamada SMART que permite monitorizar el estado del disco de forma que se pueda uno anticipar a un fallo grave pudiendo recuperar los datos antes. Pero de esto hablaremos en otro artículo.
Apuntes finales
Con las utilidades badblocks (en windows tendríamos chkdsk, con resultados similares), estamos solucionando el problema a nivel del sistema de ficheros. Esto quiere decir que nosotros lanzamos la utilidad para que se marquen los sectores defectuosos y el sistema operativo será consciente de ello, de forma que la próxima vez que vaya a escribir en los mismos, al verlos marcados, no lo haga y busque otros «sanos».
Sin embargo, es menester comentar -ya para terminar este artículo- que los propios discos duros también realizan su detección de sectores defectuosos, de tal forma que si en una escritura de un sector observan que éste tiene algún problema, directamente lo descartan y usan otro, siendo todo esto transparente al sistema operativo. Mediante S.M.A.R.T. al que hacíamos referencia antes (y del que probablemente hablaremos en un artículo próximo) se pueden consultar estos cambios, de forma que si vemos que se están produciendo muchos, podemos comenzar a plantearnos cambiar de disco duro.
Hay mucha información sobre esto en Internet. En partcicular, os recomiendo empezar por aquí.
Espero que os haya resultado útil el artículo.